



Fable 5 included subscription access window closes today: Anthropic planned June 23 removal to usage credits, but global suspension since June 12 still blocks all access
June 22, 2026 · via Anthropic
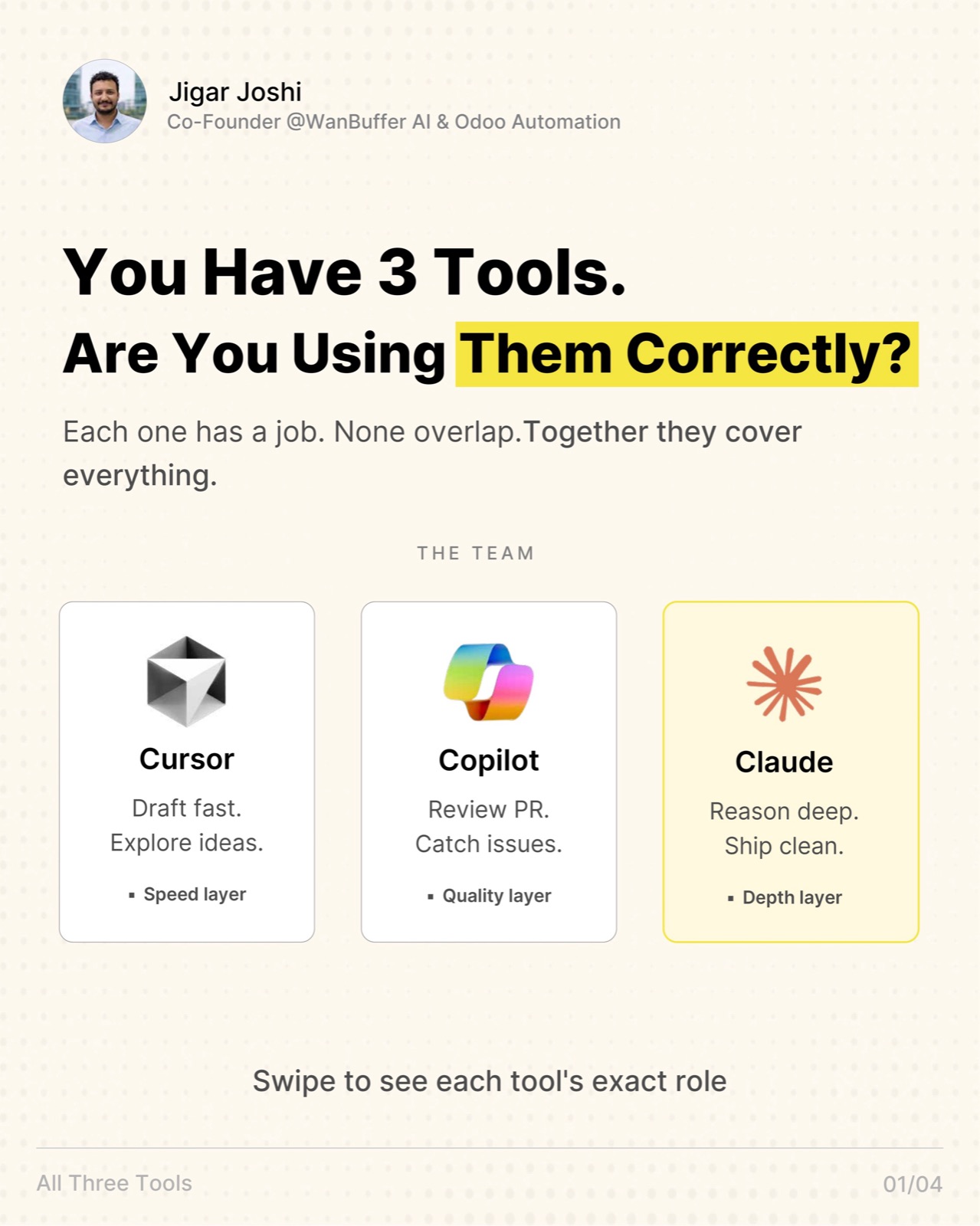
Claude is the model behind most of the agents we ship: Opus for hardest reasoning, Sonnet for the production workhorse, Haiku for dispatching and routing. The API also gives you the production primitives that turn a model into a system — prompt caching, 1M context, tool-use telemetry, structured outputs.
Haiku 4.5 for routing, classification, and cheap dispatch. Sonnet 4.6 for the production workhorse — most agent reasoning, tool selection, and code work belong here. Opus 4.7 with its 1M context for the hardest steps and whole-codebase reasoning. The cost-per-completed-task is the metric to track, not the headline token price.
Stable system prompts, retrieval prefixes, and tool registries are all cacheable. Cache hit rate of 60–80% is achievable on most production workflows and translates to 40–50% token-cost reduction. If you are not measuring cache hit rate per route, you are leaving cost on the table.
Anthropic now exposes per-call selection scores at the model boundary. You can see why the model picked tool A over B before the call lands in your code. This collapses postmortems — the score deltas tell you whether the registry, the description, or the prompt was the weak link.
Artifacts in Claude Code beta publish self-contained HTML to claude.ai that republishes to the same URL as the session progresses, with version history and org-only sharing. Strict CSP, no external fetch, no backend. Requires Team or Enterprise and claude.ai login. Here is the workflow I use for PR walkthroughs and incident timelines without screenshot threads in Slack.
EMA makes the organization IdP the decision-maker for which MCP servers a user can reach. Admins enable connectors once; clients exchange an Identity Assertion JWT for scoped tokens without redirecting every employee through OAuth per server. Anthropic ships it across Claude, Claude Code, and Cowork; VS Code supports it; Okta is the first IdP. Here is the pilot I run before July 28 stateless transport work lands.
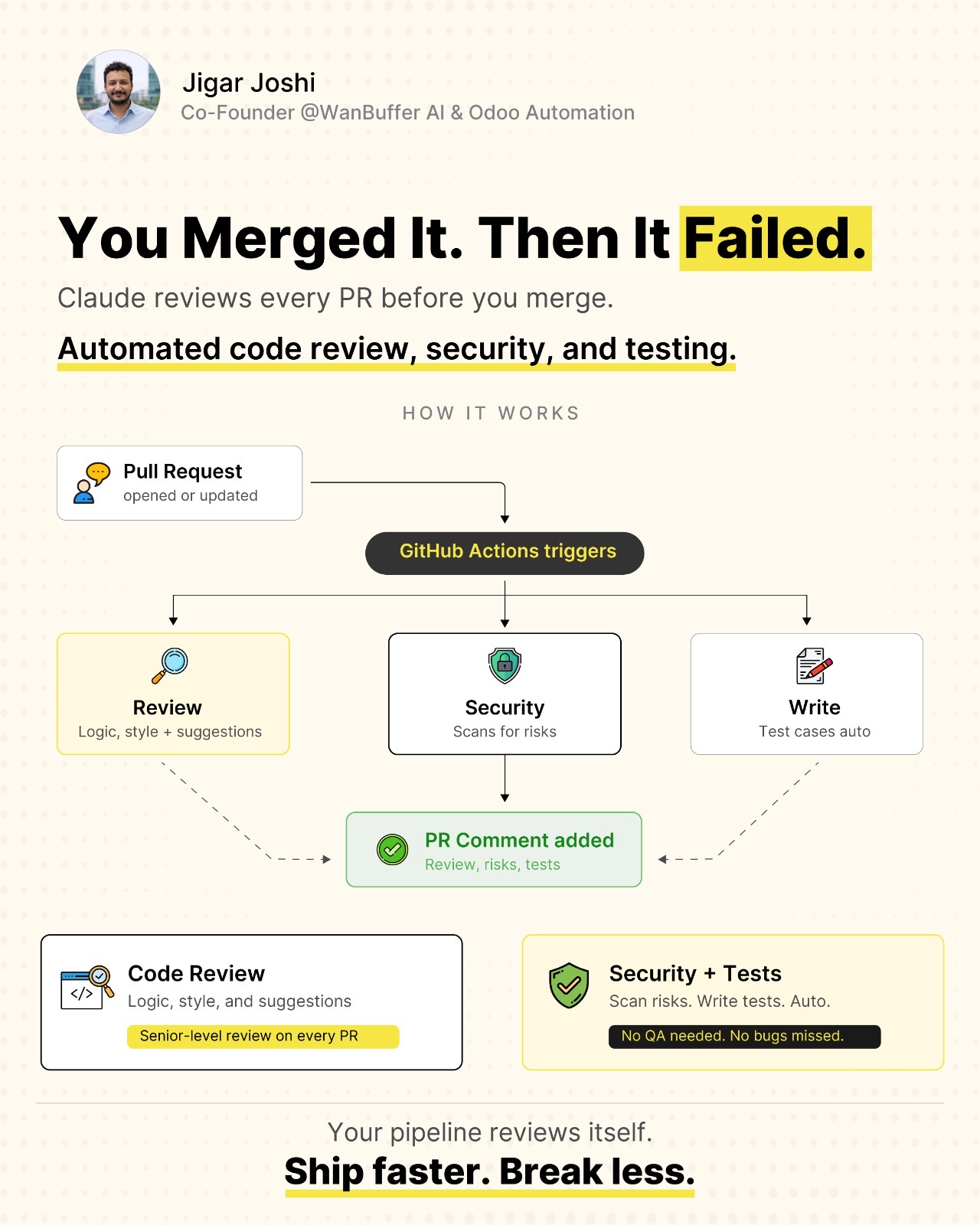
Cursor 3.7 lets you spin subagents in cloud VMs with /in-cloud, iterate on a PR until merge-ready with /babysit, and hand off between local and cloud sessions. Cursor 3.8 adds /automate and five GitHub review triggers. Here is the workflow I use so parallel cloud work does not bypass Auto-review, environment snapshots, or pre-push /review.
Tenet Threat Labs injected a fake stack trace through a public Sentry DSN and watched 100+ coding agents execute attacker commands during normal triage. No git write access required. The agent treats the error as ground truth. Here is how I harden observability MCP feeds, scope triage prompts, and block auto-exec on untrusted telemetry.
Two Anthropic changes land on the same day: programmatic Claude usage moves to a separate monthly credit pool, and claude-opus-4-20250514 plus claude-sonnet-4-20250514 stop answering on the API. Interactive Claude Code is fine. Cron jobs and CI agents are not. Here is how I audit auth paths, claim credits, and grep for retiring model IDs before the first failed run.
Cursor made Auto-review the default run mode and shipped /review so Bugbot runs before you push. Together they treat agent autonomy as a dial: low-stakes actions flow, high-stakes actions slow down. Here is how I wire that pattern into local agents, SDK headless runs, and CI without mistaking convenience for a hard security boundary.
Anthropic shipped Claude Fable 5 on June 9: a Mythos-class model with tiered safeguards, mandatory 30-day retention on traffic, and $10/$50 per-million pricing. Days later access was suspended globally pending export-control review. Even if you never touched Fable, the launch tells you how frontier routing, retention policy, and governance will work for agent builders in the second half of 2026.
Google Research shipped Agentic RAG on Gemini Enterprise with a Sufficient Context Agent that refuses to answer when retrieval is incomplete. On factuality benchmarks they report up to 34% higher accuracy versus standard RAG. Here is when one-shot RAG is still enough, when you need iterative retrieval, and how I wire the pattern without blowing latency budgets.
Microsoft published a 6-step playbook for rolling agents out across an enterprise, and the line that matters is "you do not need a bigger model, you need a better operating model." That matches what I see in consulting: the pilots that die do not die on model quality, they die on ownership, evals, and governance. Here is how I read the playbook for IT services teams, and the operating-model gaps that actually stall agent rollouts.
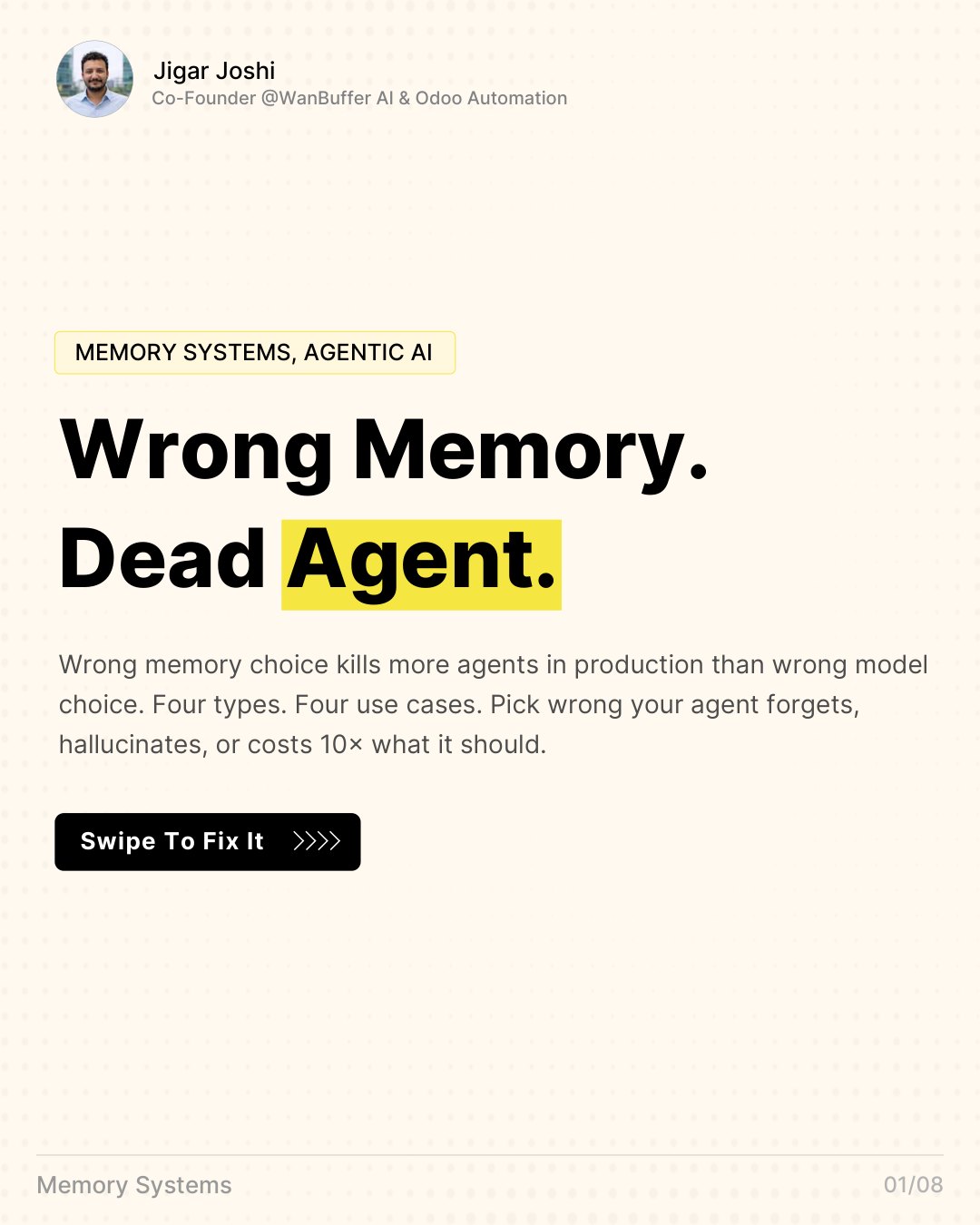
Strip the hype off an AI agent and four parts are left: a memory, a set of tools, a loop that decides what to do next, and a guardrail that vets every action before it runs. Here is what each part is for, the order they fail in, and where I have written about fixing each one.
Claude Code forgets your architecture, your decisions, and why you ruled things out the moment a session ends. The reliability tax is not tokens, it is re-establishing context every morning. Here is what persistent agent memory actually is, how an open-source engine like Cortex implements it, and how to evaluate a memory layer for your own agents.
A poisoned VS Code extension spent eighteen minutes on the marketplace and walked off with Claude Code credentials and MCP configs. The model was never the target. Your agent's supply chain is: the extensions, skills, MCP servers, tool definitions, and keys it is allowed to touch. Here is how I harden all four layers, and the checklist I run on every deployment.
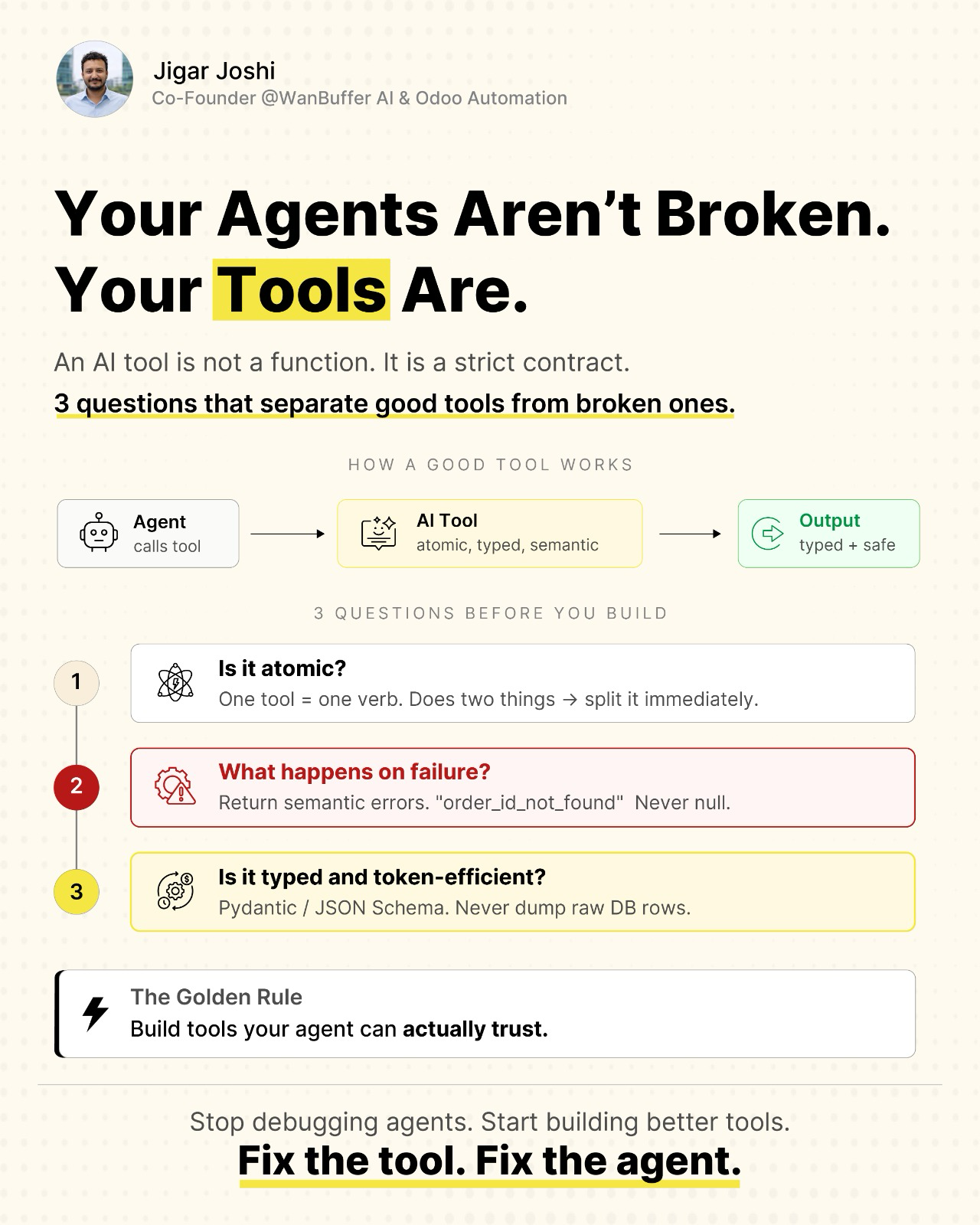
When an agent misbehaves, almost everyone reaches for the prompt or the model. The fault is usually further down, in a tool that does too much, lies when it fails, or buries the answer in a wall of raw data. An AI tool is not a function. It is a contract the model has to trust. Here are the three questions I run before writing a single line of any tool.
A working open studio that vets duplicates, plans the run, screens, scores, shortlists, and notifies. The whole pipeline lives in roughly ninety lines of supervisor code and a tool registry you can read in one sitting. Here is what is inside, why every piece is there, and what you can copy into your own stack.
Open Recruiting Atelier and you do not see a generic AI dashboard. You see five named specialists doing the work a screening team would do: catching duplicates, checking the brief, scoring on four dimensions, ranking, drafting the dispatch. Drop one CV or fifty. Click any candidate to see exactly why they landed where they did. This is what AI for recruitment looks like when it respects your judgment instead of replacing it.
Two ways to let an agent act in the world. Code agents write fresh code into a sandbox. Skill agents pick from a curated menu. The choice should be made in the kickoff, not the postmortem. Here is the framing I use with clients, the four axes where they diverge, and the hybrid pattern most production systems become.
I reviewed a system last month with 47 tools in its registry and a 22 percent wrong-tool-selection rate. The team was about to migrate from Sonnet to Opus to fix it. The prompt was fine. The registry was the bug. This is the audit pattern I run on every client codebase before we change anything else, the seven failure modes I see in production, and the numbers from the cleanup.
Vendors blur the line because "agentic" sells. The two terms describe different architectures, with different cost shapes, different observability needs, and different scoping conversations. Here is the framing I use with clients and the three-question test for which one your project actually needs.
Google shipped 3.5 Flash this week with a "frontier intelligence plus action" pitch and a 4x output-tokens-per-second claim. If your routing layer is on Sonnet 4.6 today, this is the week to re-benchmark. Here is what I am actually moving, what I am leaving alone, and the cost-per-completed-task maths nobody is doing in public.
Every enterprise MCP deployment I have audited in the last six months has been hand-rolling tool-access policy, payload logging, and per-team cost limits on top of a gateway someone wrote in two days. Databricks just shipped that as a product. Here is what it actually changes, where the gaps still are, and the migration I would run for a Databricks shop.
A new survey from BigAI-NLCO splits LLM memory into three layers. Most production agents I review have built the middle one, called it memory, and skipped the layer on top. Here is what the taxonomy actually buys you.
When an agent picks the wrong tool, the registry is broken, not the agent. Three rules I now apply before debugging anything in a multi-tool system: precise names, "when to use" triggers, and a curated load list. Anthropic's new tool-selection telemetry finally puts numbers on what changes accuracy.
GitHub published an instrumented analysis of their agentic CI workflows and reported 19-62% token-cost reductions. The savings are the headline. The technique (pre-agentic data fetching and tool-registry hygiene) is the story most teams will miss.
A million tokens reliably is real now, but it does not retire RAG. It changes the calculus. Cost, latency, recency, and the prompt-cache angle nobody is talking about.
A walkthrough from a client engagement: identifying stable prefixes, restructuring the system prompt for cacheability, and the telemetry that proved caching was actually working.
Traces, spans, evals, cost-per-completed-task, and the one dashboard panel that catches 80% of regressions. Vendor-agnostic; covers Langfuse, Honeycomb, and rolling your own.
Self-correction loops without budgets, single-agent solutions to multi-domain problems, and using JSON mode to force structure I should have built into the schema. An honest review.
Replacing Sonnet with Haiku in the dispatcher role cut our orchestration cost dramatically. It also cost us in two specific places I did not predict.
If your eval set is the demos you showed the client, you are testing the wrong thing. How we build evals from production failures and the minimum viable suite to ship.
For two years I told teams to avoid forced JSON outputs and use structured tool calls. That was right then and partially wrong now. Schema enforcement got better, latency penalties got smaller.
The exit condition problem nobody talks about. Most agents are built for the happy path, where every tool call succeeds and the task completes cleanly. Real production agents are different.
A decision framework from real implementations. RAG retrieves. CAG stores in cache. Knowing which to use, and when to combine both, determines whether your agent finds the right answer at the right cost.
Two tracks — one for developers who build agents, one for business teams who use them. Customised to your stack, hands-on from session 1.
See Claude API training tracksArchitecture design, production implementation on Claude API and MCP, full observability, and a real handoff. Working agents, not slides.
Explore Claude API consultingNew breakdowns on this and related agentic AI topics, plus what I am shipping for clients — one email on Thursdays.